折腾 NPU·第0章 —— Intel NPU 概述与 Level-Zero
最近入了台 Thinkbook 14p 2024,CPU 是 Intel Ultra5 125H,内有一枚 3720 NPU 芯片,可用于实现低功耗模型推理。藉此机会我深入了解了 NPU 开发的相关知识,以此系列为记。
NPU vs GPU
NPU 全称为 Neural Processing Unit 即神经处理单元,顾名思义即可优化加速神经网络运算的处理器芯片。在intel-npu-acceleration-library 的文档 中有一小章专门介绍了 NPU 的架构:
The Intel NPU is an AI accelerator integrated into Intel Core Ultra processors, characterized by a unique architecture comprising compute acceleration and data transfer capabilities. Its compute acceleration is facilitated by Neural Compute Engines, which consist of hardware acceleration blocks for AI operations like Matrix Multiplication and Convolution, alongside Streaming Hybrid Architecture Vector Engines for general computing tasks.
此处加粗的部分便是 NPU 相较于其他芯片的亮点,即将神经网络中常见的算子(如矩阵乘法、卷积等)特化至硬件中,从而以较低的功耗高效执行相关运算。
与 GPU 相比,NPU 的特化程度更高,计算通用性更低。开发者可以借助 CUDA 或 SPIRV 为 GPU 编写算子,从而让 GPU 执行任意代码。相比之下,使用 NPU 更像是在搭积木。NPU 预设好了一套基础算子,通过堆叠这些算子开发者得以构建多样化的模型。但 NPU 不支持自定义算子,因此并不是所有模型都能转换成 NPU 上可运行的版本。
NPU 侧重于 AI 模型的推理,而 GPU 即可用于推理也可用于训练。Ultra5 的 NPU 原生支持 FP16 乃至 int8/int4 等低精度运算,从而能够运行量化后的模型,契合当下模型推理的实践。而另一方面,NPU 缺乏对 FP32 的有效支持,在模型训练方面不如 GPU。
NPU 技术栈
如果在网上查找 NPU 编程的相关资料,你会看到各种各样的库或概念,如 OpenVINO、DirectML、ONNX Runtime、Level-Zero、OneAPI 等等。它们分别是什么呢?
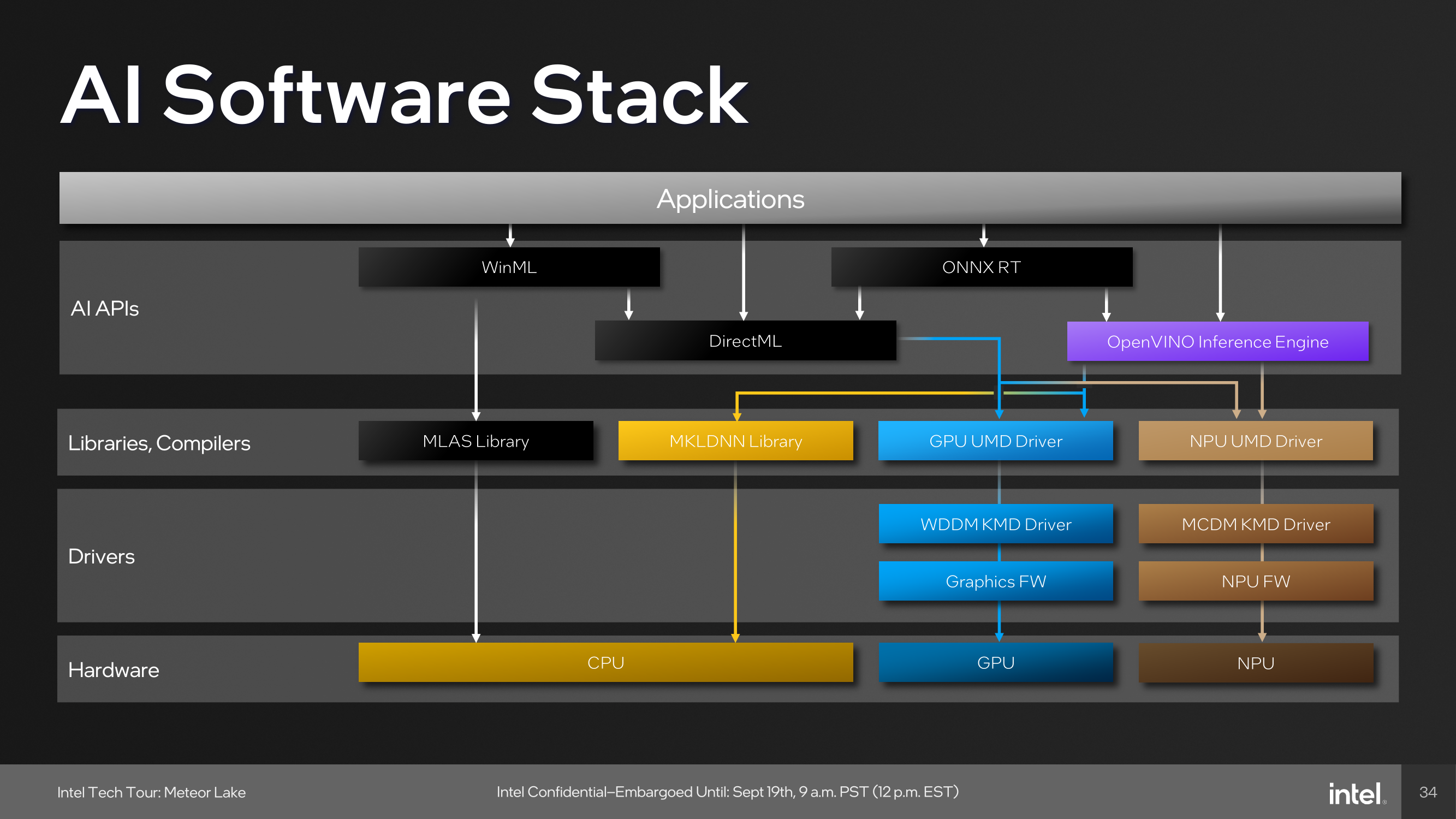
我们可以借助上图理解,图中把 NPU 的技术栈分为了三层:
内核态驱动(KMD Driver) 这是离用户最远,也是最接近硬件的部分,运行在操作系统内核态直接与硬件打交道,可以不必深入了解。
用户态驱动(UMD Driver) 这是承上启下的一部分。上层用户通过调用 UMD Driver 提供的 API,可以查询 NPU 硬件的相关信息以及运行模型。对于 Intel NPU 而言,UMD Driver 提供的 API 叫 OneAPI,实现了 OneAPI 的库叫做 Level-Zero。Level-Zero 是用户可访问的最底层的库,它所提供的 API 也是最原始的。
用户库(AI Libraries) 直接使用 Level-Zero 编程虽然可行,但是非常繁琐。因此,各方推出了一些 high-level 的 AI 库,以方便 AI 研究者开发。它们都有如下特点:
- 支持多种编程语言 大多支持 C++ 和 Python,以方便不同背景的开发者;
- 统筹多种硬件 提供统一的接口调用 CPU、GPU 和 NPU 资源,并有自己的模型中间语言(IR),从而实现异构计算;
- 从通用深度学习库编译模型 提供从 PyTorch、Tensorflow 到自己 IR 的模型编译器,以方便训练好的模型在自己生态系统中的推理部署。
常见的一些库有:
- DirectML Microsoft 推出的,仅支持 Windows 平台,但是支持多种厂商的硬件;
- ONNX Runtime ONNX 是一种标准的 AI 模型格式,它的运行时目前也支持了 NPU;
- OpenVINO Intel 推出的,跨操作系统,但仅支持 Intel 自己的硬件。
+--> [DirectML]
|
[NPU HW] <-> [KMD/UMD Driver] <-> [Level-Zero] <--OneAPI--+--> [OpenVINO]
|
+--> [ONNX Runtime]
Hacking with Level-Zero
上图总结了 NPU 常见库的相互联系。作为 AI 研究者,了解顶层 AI 库的一种即可满足日常使用。但本系列将深入挖掘更底层的 OneAPI,直接与 Level-Zero 交互。通过这么做我们将探索三个问题:
- 直接访问 Level-Zero 是否能构建更轻量级的程序? 我们知道 OpenVINO 等库包含了诸多与实际推理无关的功能,如 PyTorch 到 IR 的编译器、为统筹异构硬件所创建的抽象层等。这些部分方便了日常开发调试,但在程序分发时却成为了负担。一是打包时会增大程序体积或有依赖问题,二是会增大程序首次启动的开销。如果用户只是想在自己特定的 NPU 上运行一个特定的模型,不考虑异构也不考虑硬件版本问题,直接访问 Level-Zero 是否可以进一步优化我们的程序?
- Level-Zero 是否有上层 AI 库访问不到的隐藏功能? NPU 及相关生态目前还处于发展早期,部分功能可能处于测试阶段,因而没有在上层暴露出来。比如在目前,并没有 Intel 之外的人成功将 Stable Diffusion 通过 OpenVINO 转换成 NPU 可运行的格式,而在 openvino-ai-plugins-gimp 一库中,Intel 也仅以黑盒的方式提供了这一权重。由此可见,OpenVINO 所能处理的格式与 NPU 真正能运行的格式存在一定差距。
- 是否能让 llama.cpp/ggml 使用 NPU? llama.cpp 及其背后的 ggml 将大模型优化到了极致,实现了在低端硬件上的大模型推理,但目前它们尚不支持 NPU。
由于 Level-Zero 靠近底层,网上能找到的文档和例子都很少,因此在后续文章中,我会通过逆向 OpenVINO 的代码来了解 Level-Zero 相关的编程。
作者:hsfzxjy
链接:
许可:CC BY-NC-ND 4.0.
著作权归作者所有。本文不允许被用作商业用途,非商业转载请注明出处。

OOPS!
A comment box should be right here...But it was gone due to network issues :-(If you want to leave comments, make sure you have access to disqus.com.