Diving from the CUDA Error 804 into a bug of libnvidia-container
Several users reported to encounter "Error 804: forward compatibility was attempted on non supported HW" during the usage of some customized PyTorch docker images on our GPU cluster.
At first glance I recognized the culprit to be a version mismatch between installed driver on the host and required driver in the image. The corrupted images as they described were built targeting CUDA == 11.3 with a corresponding driver version == 465 1, while some of our hosts are shipped with driver version 460. As a solution I told them to downgrade the targeting CUDA version by choosing a base image such as nvidia/cuda:11.2.0-devel-ubuntu18.04, which indeed well solved the problem.
But later on I suspected the above hypothesis being the real cause. An observed counterexample was that another line of docker images targeting even higher CUDA version would run normally on those hosts, for example, the latest ghcr.io/pytorch/pytorch:2.0.0-devel built for CUDA == 11.7. This won’t be the case if CUDA version mismatch truly matters.
Afterwards I did a bit of research concerning the problem and learnt some interesting stuff which this post is going to share. In short, the recently released minor version compatibility allows applications built for newer CUDA to run on machines with some older drivers, but libnvidia-container doesn’t correcly handle it due to a bug and eventually leads to such an error.
Towards thorough comprehension, this post will first introduce the constitution of CUDA components, following with the compatibility policy of different components, and finally unravel the bug and devise a workaround for it. But before diving deep, I’ll give two Dockerfile samples to illustrate the problem.
Reproduction Samples
The host reported as problematic has 8x GeForce RTX 3090 with driver version 460.67 and CUDA 11.2. Here is an image with torch == 1.12.1 built for CUDA 11.3 and fails on the host:
FROM nvidia/cuda:11.3.0-cudnn8-devel-ubuntu20.04
RUN apt update -y && apt install -y python3 python3-pip
RUN pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
ENTRYPOINT ["python", "-c", "import torch; print(torch.rand(2, 3).cuda())"]
By contrast below is an image with torch == 2.0.0 built for CUDA 11.7 and runs normally:
FROM ghcr.io/pytorch/pytorch:2.0.0-devel
ENTRYPOINT ["python", "-c", "import torch; print(torch.rand(2, 3).cuda())"]
For convenience I also write a Makefile to combine the process of building and running either image:
good:
docker build -t good -< Dockerfile_good
docker run --gpus='"device=0"' --rm -it good
bad:
docker build -t bad -< Dockerfile_bad
docker run --gpus='"device=0"' --rm -it bad
With the Makefile you can run make good or make bad to see respective results:
$ make good
tensor([[0.1245, 0.2403, 0.9967],
[0.5950, 0.1597, 0.1985]], device='cuda:0')
$ make bad
<string>:1: UserWarning: Failed to initialize NumPy: numpy.core.multiarray failed to import (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:68.)
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/usr/local/lib/python3.8/dist-packages/torch/cuda/__init__.py", line 217, in _lazy_init
torch._C._cuda_init()
RuntimeError: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW
make: *** [bad] Error 1
We start off touring from the constitution of CUDA.
Components of CUDA
When talked about the term “CUDA”, two concepts “CUDA Toolkit” and “NVIDIA Display Drivers” are usually mixed up. This figure 2 illustrates their distinction as well as the cascading relationship:
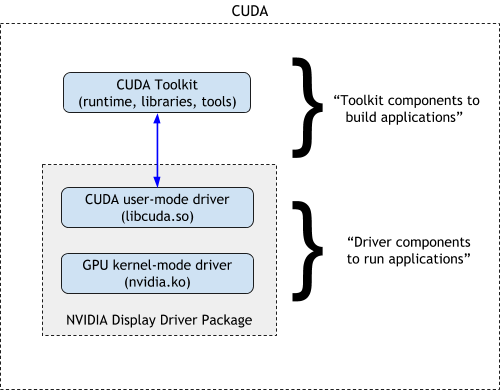
The driver at low level bridges the communication between softwares and underlying NVIDIA hardwares. The toolkit instead lies at a higher level to provide convenience for easy GPU programming.
If we take a closer look at the driver, we can see it decomposed into two secondary components “user-mode driver or UMD (libcuda.so)” and “kernel-mode driver or KMD (nvidia.ko)”. The KMD runs in OS kernel to do the most intimate contact with the hardware, while the UMD as an abstraction provides API to communicate with the kernel driver.
Generally, the applications compiled by CUDA toolkit will dynamically search and link libcuda.so during starting, which under the hood dispatches user requests to the kernel as illustrated below:
So far so good, if only the compiler in toolkit agrees on APIs with the targeting driver.
Sadly, that is not the norm. In real world, developers compile the programs on one machine and dispatch them to run on others, expecting those programs compiled by a specific version of CUDA toolkit could run on a wide variety of hardwares, or otherwise users would complain about the corrupted binaries.
Towards this guarantee, several compatibility policies are induced.
CUDA Compatibility Policies
Before we introduce the policies, we should know about how the components are versioned. The CUDA toolkit and the drivers adopt different version schemes, with the toolkit versioned like 11.2 and drivers like 460.65. Therefore, “driver 460.65” refers to the version of libcuda.so and nvidia.ko; similarly, when somebody says “CUDA 11.2”, it’s the toolkit version being mentioned.
NVIDIA devises multiple rules to ensure user binaries would work on a wide range of driver-hardware combinations, which can be grouped into two categories, i.e., toolkit-driver compatibility and UMD-KMD compatibility.
Toolkit-driver compatibility
These policies constrain that binaries compiled by a specific CUDA toolkit can run on what version of driver.
Basically we have the “Backward Compatibility”. Each CUDA toolkit has a so-called toolkit driver version 3. Binaries compiled by that toolkit are guaranteed to run on drivers newer than the toolkit driver version. For example, the toolkit driver version of CUDA 11.2 is 460.27.03, which means binaries compiled by CUDA 11.2 should work on any driver >= 460.27.03. This is the most fundamental and agelong policy.
From CUDA 11 onwards, another policy named “Minor Version Compatibility” 4 was proposed. This policy allows binaries compiled by toolkits with the same major version to a the same driver version requirement. For example, binaries compiled by CUDA 11.0 would work on driver >= 450.36.06. Since CUDA 11.2 has the same major version with CUDA 11.0, binaries compiled by CUDA 11.2 could also work on driver >= 450.36.06 5.
The backward compatibility ensures compiled binaries would work on machines shipped with drivers of future version, while the minor version compatibility reduces the necessity of upgrading drivers to run some newly compiled binaries. Generally, a binary compiled by CUDA toolkit $X.Y$ should work with driver with version $M$, if either of the following satisfies:
- CUDA toolkit $X.Y$ has toolkit driver version $N$ and $M \geq N$;
- $X \geq 11$ and a CUDA toolkit $X.Y_2$ has toolkit driver version $N_2$ and $M \geq N_2$.
However, the above policies only consider the relationship between CUDA toolkit and drivers. What if the user-mode and kernel-mode drivers have diverged version? This is where UMD-KMD compatibility applies.
UMD-KMD compatibility
In ideal case, kernel-mode driver should always work with user-mode driver with the same version. But upgrading kernel-mode drivers is sometimes tricky and troublesome, of which some users such as data center admins could not take the risk. Towards this consideration, NVIDIA devised the “Forward Compatibility” to allow old-versioned KMD to cooperate with new-versioned UMD under some circumstance.
Specifically, a kernel-mode driver would support all user-mode drivers releases during its lifetime. For instance, the driver 418.x has end of life (EOL) in March 2022, before which driver 460.x was released, then KMD 418.x would work with UMD 460.x. The compatibility does not involve anything at a higher level such as CUDA toolkit.
It’s worth noting that, this policy does not apply to all GPU hardwares but only a fraction of them. NVIDIA has limited forward compatibility to be applicable for systems with NVIDIA Data Center GPUs (the Tesla branch) or NGC Server Ready SKUs of RTX cards 6. If you own a GeForce RTX 3090, like in my scenario, you won’t enjoy this stuff.
Summary of Compatibility
Let’s make a quick review for the various types of compatibility policies. If you have a binary compiled by CUDA $X.Y$, a host with UMD (libcuda.so) versioned $M$ and KMD (nvidia.ko) versioned $M'$, then they would work fine if both of the two conditions hold:
- The UMD and KMD is compatible. Specifically, either
- the GPU supports forward compatibility (Tesla branch or NGC ready), and driver $M$ comes before the EOL of driver $M'$ (the forward compatibility); or
- $M = M'$.
- The CUDA toolkit and UMD is compatible. Specifically, either
- CUDA toolkit $X.Y$ has toolkit driver version $N$ and $M \geq N$ (the backward compatibility); or
- major version $X \geq 11$ and there exists another toolkit $X.Y_2$ with toolkit driver version $N_2$ and $M \geq N_2$ (the minor version compatibility).
Generally, validating the above conditions should help whenever you run in any compatibility problems.
Back to Our Problem
So, what’s wrong with the docker image bad? With above rules in hands we can perform a simple analysis.
Could it be a toolkit-driver incompatibility? Probably NO. According to Table. 1 here, the minor version compatibility applies with CUDA 11.x and driver >= 450.80.02, which our driver version 460 satisfies, let alone binary compiled by CUDA 11.7 working like a charm in the case of docker image good.
It should be due to a KMD-UMD incompatibility, namely, the version of libcuda.so and nvidia.ko is incompatible. Since forward compatibility is not applicable for RTX 3090, we are expecting condition 1.2 holds, where libcuda.so and nvidia.ko should have the same version – this obviously was not the case.
How nvidia driver works with docker?
A process in a container is technically a special process on the host, which shares the same model as other processes do to interact with GPU drivers. Since KMD runs in kernel and not interfered by user space, all programs regardless of on host or in containers are communicate with the same KMD.
By contrast, a program can flexibly choose which user-mode driver to link against. It can either link to the UMD installed along with the KMD on the host, or brings its own UMD during packaging and distribution.
We can list out all the UMDs in a running good container with the command:
$ docker run --gpus='"device=0"' --rm -it --entrypoint= good bash
root@3a19f802a459:/workspace# find / -name 'libcuda.so*' -exec bash -c "echo {} -\> \`readlink {}\`" \; 2>/dev/null
/usr/lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.460.67
/usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
/usr/lib/x86_64-linux-gnu/libcuda.so.460.67 ->
Looks like there is only one copy of libcuda.so that lies in /usr/lib/x86_64-linux-gnu/ with version 460.67. However, such libcuda.so was not packed with the docker image from the beginning. The library disappears if you omit the --gpus argument:
$ docker run --rm -it --entrypoint= good bash
root@3a19f802a459:/workspace# find / -name 'libcuda.so*' -exec bash -c "echo {} -\> \`readlink {}\`" \; 2>/dev/null
root@3a19f802a459:/workspace#
In fact, the library exists on the host and is injected into the container by docker runtime during the startup. This post demonstrates the injection process by viewing docker’s log. Mounting libcuda.so from the host will maximally ensures the KMD-UMD correspondence aligned.
Now that the docker runtime would choose a native UMD, why did the image bad fail?
The internal of image bad
We can likewise check the UMDs in a running bad container as belows:
$ docker run --gpus='"device=0"' --rm -it --entrypoint= bad bash
root@15f9b3c915b8:/# find / -name 'libcuda.so*' -exec bash -c "echo {} -\> \`readlink {}\`" \; 2>/dev/null
/usr/lib/x86_64-linux-gnu/libcuda.so.465.19.01 ->
/usr/lib/x86_64-linux-gnu/libcuda.so.1 -> libcuda.so.465.19.01
/usr/lib/x86_64-linux-gnu/libcuda.so -> libcuda.so.1
/usr/lib/x86_64-linux-gnu/libcuda.so.460.67 ->
/usr/local/cuda-11.3/compat/libcuda.so.465.19.01 ->
/usr/local/cuda-11.3/compat/libcuda.so.1 -> libcuda.so.465.19.01
/usr/local/cuda-11.3/compat/libcuda.so -> libcuda.so.1
/usr/local/cuda-11.3/targets/x86_64-linux/lib/stubs/libcuda.so ->
OOPS!!! Looks like there’s big difference here. We could derive two observations from the result:
- There is already a
libcuda.sobundled inside the image at/usr/local/cuda-11.3/compat/libcuda.so.465.19.01, with a higher version of465.19.01. - During startup, both the native
libcuda.so.460.67and the bundledlibcuda.so.465.19.01are symlinked under/usr/lib/x86_64-linux-gnu/, and most importantly, it’s the bundled one being linked aslibcuda.soand chosen by the program.
And that is the reason why the docker image bad violates KMD-UMD compatibility!
The bug of libnvidia-container
Such misbehavior is a consequence of a bug of libnvidia-container. But before we talk about it, let’s take a step back to see what the directory /usr/local/cuda-X/compat does and why should it exist.
Actually the compat directory is part of the CUDA compat package, according to the official docs, which exists to support the forward compatibility 7. The official base image nvidia/cuda:11.3.0-cudnn8-devel-ubuntu20.04 had this package built in, which contains a higher version UMD libcuda.so.465.19.01 in case of an older-versioned KMD running on the host. As aforementioned, to apply forward compatibility there exists requirement on the underlying hardware. When the requirement unsatisfied, such as for our RTX 3090 GPUs, the libcuda.so from compat package should hopefully not be linked against.
Unfortunately, current release of nvidia-docker would roughly attempt to apply forward compatibility, regardless of whether the GPUs meet the limitation.
The problem was encountered and studied by Gemfield who posted an article PyTorch 的 CUDA 错误:Error 804: forward compatibility was attempted on non supported HW as explanation. Gemfield observed nvidia-docker would simultaneously symlink both the native UMD on host and the compat UMD in docker image under /usr/lib/x86_64-linux-gnu/, and brutely choose the one with higher version as the libcuda.so.1, against which user programs would link.
Obviously this behavior is neither in line with forward compatibility nor with minor version compatibility. Gemfield opened an issue NVIDIA/nvidia-docker#1515 for discussion, where the author guessed it was a bug of libnvidia-container and another issue NVIDIA/libnvidia-container#138 was referred. Both issues are not yet resolved up till now.
The workaround is simple – if there’s no compat package, the compat UMD won’t be applied. We can either remove the compat package or brutely delete the /usr/local/cuda-X/compat directory to let it work:
FROM nvidia/cuda:11.3.0-cudnn8-devel-ubuntu20.04
RUN apt update -y && apt install -y python3 python3-pip
RUN pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
RUN apt purge cuda-compat-11-3 -y
# OR
RUN rm -rfv /usr/local/cuda-11.3/compat/
ENTRYPOINT ["python", "-c", "import torch; print(torch.rand(2, 3).cuda())"]
FROM nvidia/cuda:11.3.0-cudnn8-devel-ubuntu20.04
RUN apt update -y && apt install -y python3 python3-pip
RUN pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
ENTRYPOINT ["python", "-c", "import torch; print(torch.rand(2, 3).cuda())"]
FROM nvidia/cuda:11.3.0-cudnn8-devel-ubuntu20.04
RUN apt update -y && apt install -y python3 python3-pip
RUN pip install torch==1.12.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
RUN apt purge cuda-compat-11-3 -y
# OR
RUN rm -rfv /usr/local/cuda-11.3/compat/
ENTRYPOINT ["python", "-c", "import torch; print(torch.rand(2, 3).cuda())"]
$ make bad
tensor([[0.0059, 0.6425, 0.2299],
[0.2306, 0.5954, 0.0226]], device='cuda:0')
Epilogue
This article elaborates the cause and workaround of CUDA Error 804 when NVIDIA GPUs working with docker. As preknowledge, I introduced the consistution of CUDA, the various categories of CUDA compatibility policies, and how the docker runtime deals with GPU driver. The culprit was discovered to be a bug or deficiency of libnvidia-container, which mishandled forward compatibility and minor version compatibility and was not yet resolved. As a workaround, one can remove the CUDA compat image inside the image to avoid forward compatibility being applied and light the minor version compatibility.
References
- PyTorch 的 CUDA 错误:Error 804: forward compatibility was attempted on non supported HW
- CUDA Compatibility
- Table 3. CUDA Toolkit and Corresponding Driver Versions
- Difference between the driver and runtime APIs
- CUDA Driver Lifecycles
- The latest nvidia-container-toolkit caused inconsistent cuda version and 804 error. #1515
- Invalid libcuda.so.1 symlink under CUDA Enhanced Compatibility #138
- https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#id4
- https://docs.nvidia.com/deploy/cuda-compatibility
- https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html#id4
- Sometimes called “Enhanced Compatibility” in old context.
- To be accurate, with some limitations but should be ignorable for machine learning scenario.
- https://docs.nvidia.com/deploy/cuda-compatibility/#forward-compatible-upgrade:~:text=Forward%20Compatibility%20is%20applicable%20only%20for%20systems%20with%20NVIDIA%20Data%20Center%20GPUs%20or%20select%20NGC%20Server%20Ready%20SKUs%20of%20RTX%20cards.
- RECALL: it’s part of UMD-KMD compatibility
Author: hsfzxjy.
Link: .
License: CC BY-NC-ND 4.0.
All rights reserved by the author.
Commercial use of this post in any form is NOT permitted.
Non-commercial use of this post should be attributed with this block of text.
